

O GitHub Copilot iniciou uma atualização estrutural em seu ecossistema para otimizar o uso de tokens e melhorar a eficiência operacional das sessões de codificação. A mudança, detalhada em recente postagem no blog da empresa, foca em reduzir a redundância de dados enviados aos modelos e aprimorar a capacidade de escolha automática do motor de IA mais adequado para cada tarefa específica.
Segundo a companhia, o objetivo central é garantir que os créditos de uso dos desenvolvedores sejam direcionados ao trabalho útil, em vez de serem gastos com o processamento de instruções repetitivas ou configurações desnecessárias. A estratégia combina melhorias no harness — o ambiente que prepara o contexto para os modelos — com a expansão da funcionalidade Auto, que seleciona o modelo de IA ideal com base na complexidade da demanda.
Refinamento do contexto e cache de prompts
O desafio de manter sessões longas de codificação reside na quantidade de informações recorrentes que precisam ser reprocessadas a cada interação. Instruções de sistema, definições de ferramentas e o histórico da conversa consomem uma fatia significativa do orçamento de tokens. Para mitigar isso, o GitHub implementou o cache de prompts, que permite reutilizar o estado do modelo para prefixos repetidos, evitando o reprocessamento constante a cada nova solicitação.
Além do cache, a ferramenta introduziu a busca de ferramentas sob demanda. Em vez de enviar todos os esquemas de ferramentas disponíveis para o modelo em cada turno, o Copilot agora carrega apenas o que é estritamente necessário para a tarefa em curso. Essa abordagem reduz drasticamente o custo fixo de cada interação, especialmente em fluxos de trabalho complexos que exigem acesso a múltiplos recursos, como operações de terminal e busca em espaços de trabalho.
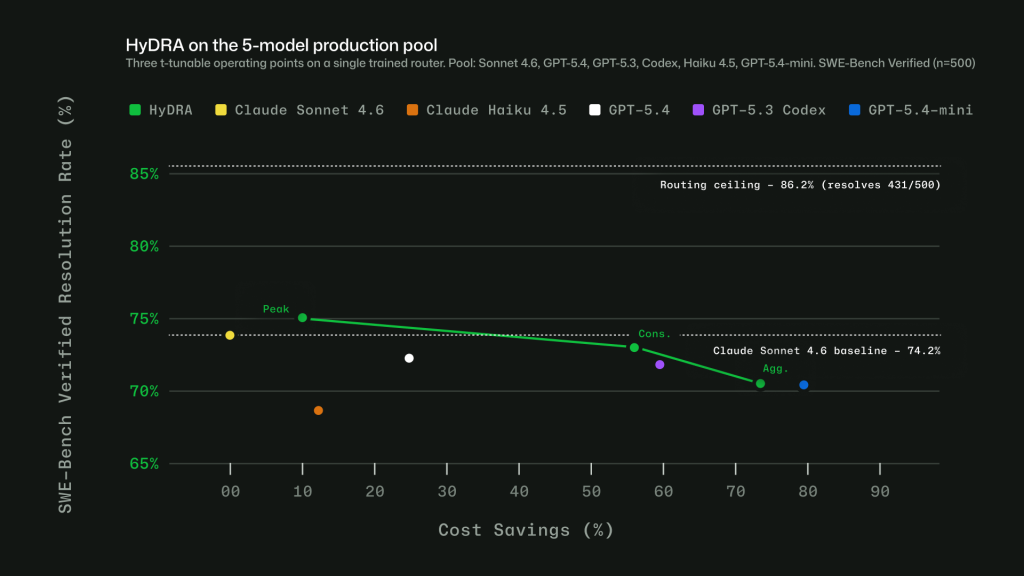
Roteamento inteligente com HyDRA
A funcionalidade Auto é a resposta do GitHub para o dilema de qual modelo utilizar. Nem toda tarefa exige o poder de raciocínio de um modelo de linguagem de ponta; muitas vezes, uma solução mais eficiente entrega o mesmo resultado com menor latência e custo. O sistema de roteamento, batizado de HyDRA, avalia fatores como a complexidade do código, a necessidade de depuração e o nível de raciocínio exigido para tomar a decisão de encaminhamento.
O sistema opera com base em sinais de saúde do sistema, como disponibilidade e tempo de resposta, e na natureza da tarefa. Ao evitar a abordagem de "tamanho único", o Copilot consegue escalar o uso de modelos mais potentes apenas quando o problema demanda, mantendo a eficiência em interações mais simples. O modelo de roteamento foi treinado para identificar pontos de divergência real entre as capacidades dos modelos, garantindo que a qualidade não seja sacrificada em prol da economia.
Implicações para o fluxo de trabalho
A mudança na gestão de modelos traz implicações diretas para a experiência do usuário e para a governança corporativa. Para as empresas, o controle administrativo agora permite definir o Auto como padrão, garantindo que a eficiência seja aplicada de forma consistente em toda a organização. Além disso, a internacionalização do roteador, que agora suporta 16 famílias de idiomas, demonstra um esforço para manter a paridade de desempenho global, com métricas de qualidade próximas ao baseline em inglês.
Para o desenvolvedor, a recomendação é manter sessões focadas e evitar a troca manual de modelos ou configurações mid-session, o que pode fragmentar o cache e anular os ganhos de eficiência. A padronização em torno do Auto tende a simplificar o uso, removendo a necessidade de ajuste manual constante e permitindo que o sistema aprenda com a intenção da tarefa.
Desafios e perspectivas futuras
Embora o roteamento automático ofereça ganhos claros de eficiência, a imprevisibilidade do comportamento do modelo em situações de borda permanece um ponto de atenção. A capacidade do sistema de aprender onde a escalada para um modelo mais forte é realmente necessária será testada à medida que a ferramenta for expandida para novos ambientes, como o GitHub App e outros IDEs.
O sucesso desta iniciativa dependerá da precisão contínua do roteador em cenários de uso real, onde as conversas mudam de contexto rapidamente. A evolução das métricas de eficiência e a transparência sobre o consumo de créditos serão fundamentais para que os usuários confiem na automação do Copilot em seus fluxos de trabalho críticos.
O movimento do GitHub reflete uma tendência mais ampla no setor de IA, onde a otimização de infraestrutura torna-se tão importante quanto a própria capacidade dos modelos. O foco agora se desloca para a eficiência operacional, garantindo que a inteligência artificial seja um recurso sustentável e integrado ao dia a dia do desenvolvimento de software.
Com reportagem de Brazil Valley
Source · The GitHub Blog


