

A eficiência operacional no uso de grandes modelos de linguagem (LLMs) esconde uma variável frequentemente ignorada por empresas e usuários: o idioma da consulta. Embora chatbots como ChatGPT, Claude e Gemini ofereçam suporte multilíngue, a forma como esses sistemas são treinados e tokenizam texto tende a favorecer o inglês, levando a um consumo maior de tokens em outros idiomas. Segundo reportagem do Xataka, isso não é uma “falha de tradução”, mas um efeito direto da tokenização e da distribuição de dados usados no treinamento.
Por que o idioma importa
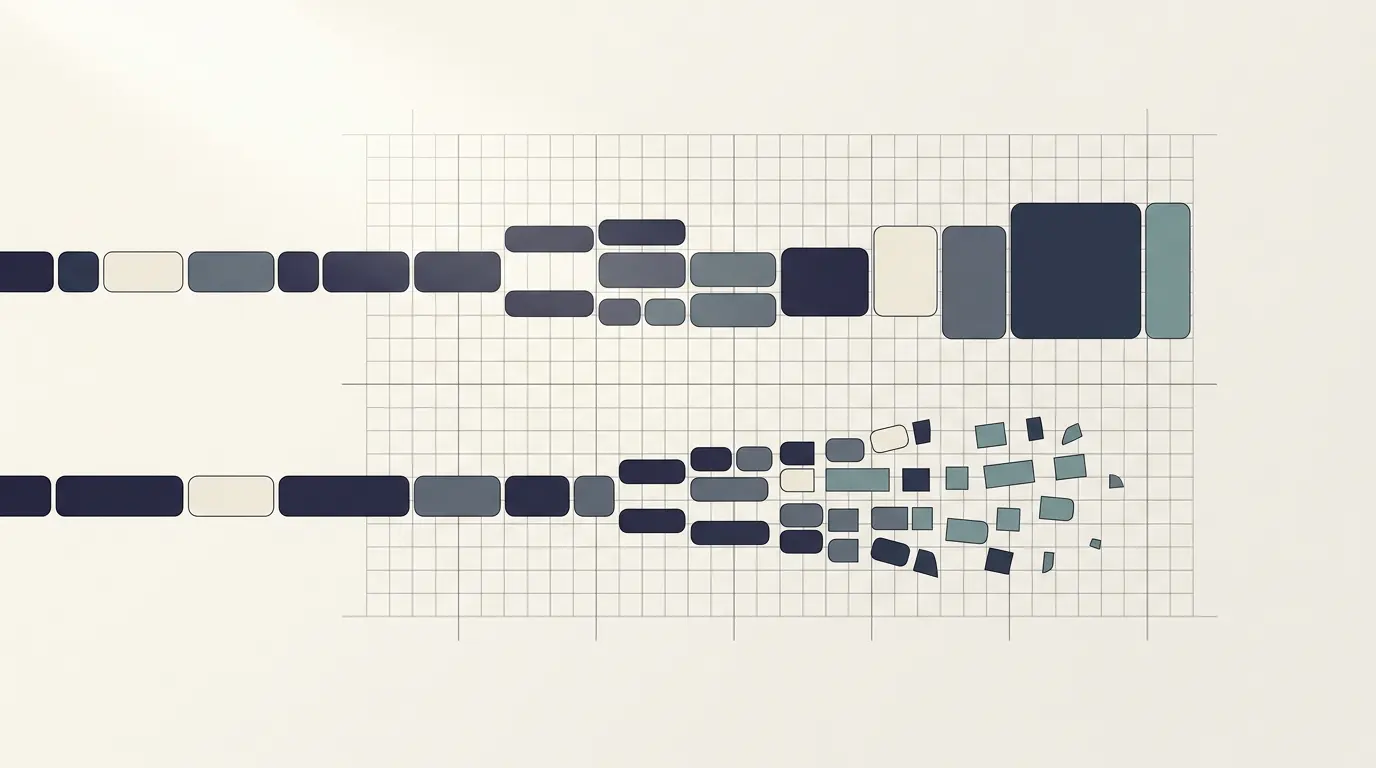
Tokenizadores convertem texto em unidades numéricas (tokens) que o modelo consegue processar. Como os conjuntos de dados de treinamento e os próprios tokenizadores de muitos LLMs são fortemente orientados ao inglês, sequências nessa língua costumam se comprimir em menos tokens. Em outras palavras, termos comuns em inglês frequentemente viram menos unidades do que seus equivalentes em outros idiomas. Exemplos simples (como respostas curtas ou palavras de alta frequência) mostram que o inglês pode “encaixar” melhor no vocabulário do tokenizador, reduzindo o custo por requisição.
O papel da tokenização na eficiência
Quando um usuário envia comandos em português ou espanhol, é comum que o texto seja segmentado em mais tokens do que ocorreria em inglês para a mesma ideia. Isso não implica uma etapa de tradução, e sim uma segmentação menos favorável, que consome mais memória e processamento. Em fluxos de trabalho com grande volume via API, esse sobrecusto se acumula e se traduz em fatura maior.
Vale notar que o impacto varia conforme provedor e tokenizador (há diferentes técnicas como BPE e SentencePiece, e vocabulários treinados em corpora distintos). Provedores vêm ajustando seus tokenizadores e modelos mais novos tendem a melhorar a eficiência em múltiplos idiomas, mas a assimetria ainda aparece com frequência, como destaca o Xataka.
Efeitos econômicos práticos
Na prática, diferenças de tokenização por idioma podem se tornar materiais em conversas longas, contextos extensos ou pipelines automatizados. Segundo a reportagem, usar inglês em prompts e respostas costuma resultar em menos tokens do que alternativas em outros idiomas — um fator que impacta diretamente a conta de API e o throughput das aplicações.
Implicações para o ecossistema local
Para desenvolvedores e empresas brasileiras, vale considerar estratégias de mitigação quando custo e desempenho são críticos: padronizar prompts técnicos em inglês, revisar padrões de resposta e medir o efeito no consumo de tokens antes de escalar. Por outro lado, essa opção cria uma barreira de entrada para equipes e públicos sem fluência, reforçando uma desigualdade de acesso que extrapola a tecnologia.
O que observar daqui em diante
Modelos e tokenizadores evoluem rapidamente. A expectativa é de ganhos graduais de eficiência em idiomas além do inglês, mas ainda não há garantia de paridade total. Para quem opera em produção, acompanhar mudanças de tokenizadores e testar o consumo por idioma continua sendo parte essencial da otimização de custos e performance.
Com reportagem do Xataka: https://www.xataka.com/robotica-e-ia/pregunta-usar-chatgpt-gemini-ingles-eficiente-ahorra-tokens-respuesta-yes
Source · Xataka


