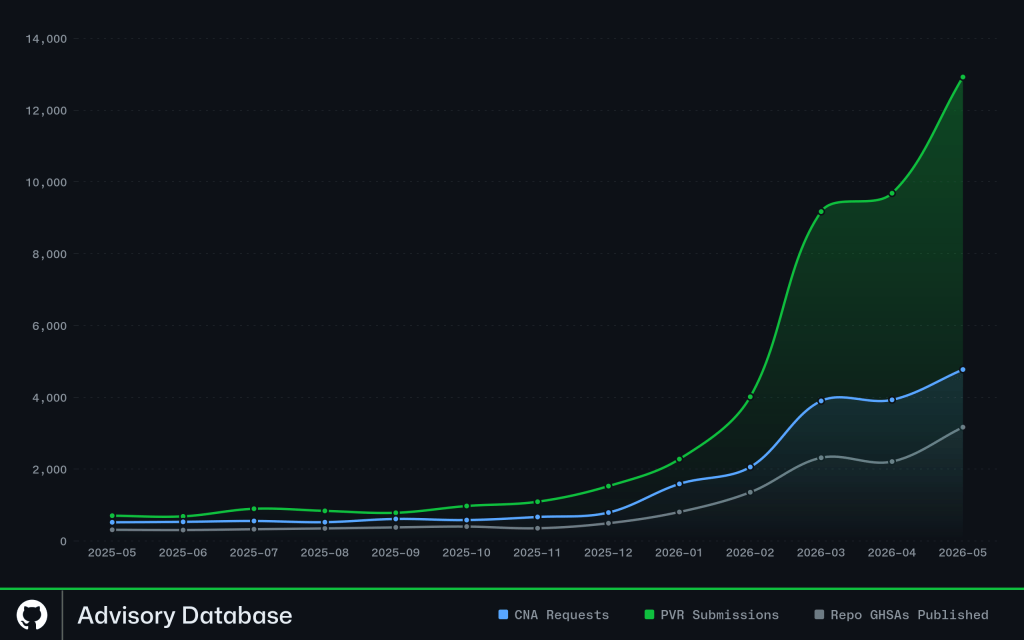
Recentemente, o GitHub Advisory Database atingiu um marco operacional sem precedentes: a publicação de 1.560 avisos de segurança revisados em um único mês. O número, que representa mais de cinco vezes a média mensal histórica da plataforma, não é um evento isolado, mas o reflexo de um ecossistema de segurança de software em franca expansão. Segundo reportagem do blog oficial do GitHub, a infraestrutura de curadoria da empresa está operando além de sua capacidade projetada, forçando uma adaptação urgente nos processos de validação e publicação.
O aumento na demanda não se limita apenas aos avisos publicados, mas abrange todo o ciclo de vida da vulnerabilidade. Desde março, a plataforma tem processado mais de 6.000 decisões mensais, incluindo atualizações e triagens de novos relatórios. A entrada de dados via relatórios privados, avisos de repositórios e solicitações de CVE (Common Vulnerabilities and Exposures) cresceu de forma exponencial, criando um gargalo que, embora não comprometa a qualidade final dos dados, impacta diretamente a agilidade na resposta a ameaças.
O novo patamar da segurança colaborativa
A mudança no volume de reportes é um sintoma direto da maturação da cultura de segurança no desenvolvimento de software. Mais repositórios adotaram a prática de reporte privado de vulnerabilidades, e pesquisadores estão, de forma mais sistemática, identificando e divulgando falhas. O que antes era um fluxo gerenciável de avisos tornou-se um desafio de escala industrial. A tese central aqui é que a transparência, embora seja um ganho líquido para a segurança global, impõe um custo operacional elevado sobre as plataformas que centralizam essa inteligência.
Historicamente, o GitHub conseguia absorver a complexidade de casos mais ambíguos — como a necessidade de reconstruir faixas de versões afetadas ou disambiguar pacotes entre diferentes gerenciadores (npm, PyPI, Maven). No entanto, com a pressão de volume atual, a fila de espera tornou-se um misto de casos simples e complexos, criando um efeito composto que retarda a publicação de todos os itens. A curadoria humana, elemento central da confiabilidade do banco de dados, tornou-se o principal gargalo logístico do sistema.
A mecânica da curadoria sob pressão
O processo de revisão no GitHub não é uma simples indexação de dados. Cada aviso passa por uma validação que inclui o mapeamento da vulnerabilidade ao pacote correto, a verificação das versões afetadas e a análise de consistência com o histórico de commits do projeto. Quando um aviso chega incompleto ou com dados contraditórios entre o CVE e o histórico do mantenedor, o esforço de curadoria aumenta drasticamente. O problema, portanto, não é de infraestrutura de rede ou pipeline de dados, mas de processamento de informação complexa.
Para lidar com esse cenário, a plataforma tem investido em ferramentas de auxílio baseadas em IA para acelerar a pesquisa inicial, mas a decisão final permanece humana. A lógica é evitar que o ganho de velocidade resulte em falsos positivos, o que, no contexto de segurança de dependências, poderia causar mais dano do que o atraso na notificação. A estratégia atual foca em otimizar o tempo de resposta para os casos mais comuns, permitindo que os especialistas humanos se dediquem apenas às ambiguidades técnicas que exigem discernimento especializado.
Stakeholders e o impacto no ecossistema
O impacto dessa mudança é sentido em toda a cadeia de suprimentos de software. Desenvolvedores que utilizam ferramentas como o Dependabot dependem da precisão e da tempestividade desses avisos para mitigar riscos em seus ambientes de produção. Embora o GitHub garanta que a qualidade dos dados revisados permanece inalterada, o aumento no tempo de publicação cria janelas de exposição mais longas. Para os mantenedores de projetos open source, a pressão é para que a documentação das vulnerabilidades seja feita com maior rigor técnico desde a origem.
Do ponto de vista dos reguladores e das empresas que consomem software open source, a dependência de bancos de dados centralizados como o do GitHub torna a eficiência dessa curadoria uma questão de risco sistêmico. A necessidade de dados estruturados, como strings de vetor CVSS completas e classificações CWE (Common Weakness Enumeration) precisas, deixa de ser uma boa prática e passa a ser uma exigência para que a automação de segurança funcione em escala nas grandes organizações.
O futuro da transparência e a escala
A grande incógnita para os próximos trimestres é se o volume de reportes continuará a crescer na mesma proporção ou se o ecossistema encontrará um ponto de equilíbrio. A tendência aponta para uma maior sofisticação na triagem, onde a priorização será cada vez mais baseada em dados de exploração ativa e risco real, em vez de apenas na ordem de chegada. O desafio de manter a transparência sem sobrecarregar os curadores é o próximo grande teste para o modelo de segurança do GitHub.
Observar a evolução das ferramentas de automação e a capacidade da comunidade em fornecer dados mais limpos será fundamental. Se a qualidade dos relatórios iniciais melhorar, o gargalo poderá ser contornado. Caso contrário, a indústria pode ter que aceitar novas formas de validação descentralizada ou um modelo de triagem mais agressivo, que priorize a velocidade em detrimento da exaustiva revisão humana que hoje define a marca do GitHub Advisory Database.
A transição para um modelo de segurança em escala não é apenas um desafio técnico, mas um ajuste cultural necessário para um mundo onde o código aberto é a base de quase toda a infraestrutura digital moderna. A forma como essa transição será gerida nos próximos meses definirá o padrão de confiança para todo o ecossistema de desenvolvimento global.
Com reportagem de Brazil Valley
Source · The GitHub Blog